BERT 이해하기
BERT 이용에 필요한 기본적인 지식들을 정리해보려고 한다. 정리 내용은 https://wikidocs.net/book/2155 를 기반으로한다. 한번씩은 읽어보는거 강력추천!

- 𝐻(𝑥)에서 𝐻는 가설(Hypothesis)을 의미하며, 𝑥와 𝑦의 관계를 𝑤와 𝑏를 이용하여 식을 세우는 일을 가설이라고한다.
머신 러닝은 𝑤와 𝑏를 찾기 위해서 실제값과 가설(H(x))로부터 얻은 예측값의 오차를 계산하는 식을 세우고, 이 식의 값을 최소화하는 최적의 𝑤와 𝑏를 찾아낸다.
- 목적 함수(Objective function): 실제값과 예측값에 대한 오차 값을 최소화하거나, 최대화하거나 하는 목적을 가진 함수
- 비용 함수(Cost function) 또는 손실 함수(Loss function) : 실제값과 예측값에 대한 오차 값을 최소화하는 함수
비용 함수(손실 함수)는 단순히 실제값과 예측값에 대한 오차를 표현하면 되는 것이 아니라, 예측값의 오차를 줄이는 일에 최적화 된 식이어야한다. 오차가 클 수록 손실 함수의 값은 커지고 오차가 작을 수록 손실 함수의 값은 작아지므로, 딥 러닝의 학습은 결국 손실 함수를 최소화하는 매개 변수인 가중치 𝑤와 편향 𝑏을 찾는 것이다. 이때 사용되는 알고리즘을 옵티마이저(Optimizer) 또는 최적화 알고리즘이라고 한다. 이 옵티마이저를 통해 적절한 𝑤와 𝑏를 찾아내는 과정을 머신 러닝에서 훈련(training) 또는 학습(learning)이라고 부른다.
행렬
행렬 곱셈의 두 가지 주요한 조건
- 두 행렬의 곱 J × K이 성립되기 위해서는 행렬 J의 열의 개수와 행렬 K의 행의 개수는 같아야 한다.
- 두 행렬의 곱 J × K의 결과로 나온 행렬 JK의 크기는 J의 행의 개수와 K의 열의 개수를 가진다.

- X: 독립 변수 행렬 혹은 입력 행렬(Input Matrix)
- Y: 종속 변수 행렬 혹은 출력 행렬(Output Matrix)
- W: 가중 행렬
- B: 편향 행렬
- 딥 러닝 모델의 총 매개변수의 개수: 해당 모델에 존재하는 가중치 행렬과 편향 행렬의 모든 원소의 수
이때 행렬의 덧셈에 해당되는 B 행렬은 Y 행렬과 크기가 같으며, 행렬 곱셈의 조건으로 인해 W 의 행은 X의 열과 W의 열은 Y의 열과 같다. 이에 출력 행렬 Y로부터 W행렬의 열의 크기가 결정된다고 할 수 있다. 입력 행렬과 출력 행렬의 크기로부터 가중치 행렬과 편향 행렬의 크기를 추정할 수 있어, 딥 러닝 모델을 구현하였을 때 해당 모델에 존재하는 총 매개변수의 개수를 계산할 수 있다.
활성화 함수(Activation Function)


은닉층과 출력층의 뉴런에서 출력값을 결정하는 함수를 활성화 함수(Activation Function)라고 한다. 신경망의 가설을 형성하는 데 필수적인 요소 중 하나로 볼 수 있다. 여기서 은닉층은 더 어려운 문제를 풀기 위해 입력과 출력층 사이에 추가된 층이다. 출력층과 입력층 두개만 있다면 계산할 수 있는 게 한정적일 것이다. 때문에 은닉층을 추가하여 더 어려운 문제를 풀수 있도록 하고, 은닉층의 개수는 2개일 수도 있고, 수십 개일수도 있다.
활성화 함수 특징
활성화 함수는 비선형 함수여야 한다. 선형 함수란 출력이 입력의 상수배만큼 변하는 함수(ex. 𝑓(𝑥)=𝑤𝑥+𝑏)다. 쉽게 말해 선형함수는 직선 1개로 그릴수 있는 함수이고, 비선형 함수는 직선 1개로 그릴수 없는 함수를 말한다.
만약 선형함수라면?
활성화 함수는 𝑓(𝑥)=𝑤𝑥 일때, 은닉층을 두 개 추가한다고 하면, 출력층을 포함해서 𝑦(𝑥)=𝑓(𝑓(𝑓(𝑥)))가 된다. 이는 𝑤×𝑤×𝑤×𝑥 가 되고, 𝑤의 세 제곱값을 𝑘라고 정의해버리면 𝑦(𝑥)=𝑘𝑥와 같이 다시 표현이 가능하다. 이 경우, 선형 함수로 은닉층을 여러번 추가하더라도 1회 추가한 것과 차이가 없음을 알 수 있다. 이 때문에 인공 신경망의 능력을 높이기 위해서는 은닉층을 계속해서 추가해야 하는데, 만약 활성화 함수로 선형 함수를 사용하게 되면 은닉층을 쌓을 수가 없게 된다.
그렇다고 모든 층이 선형함수를 사용하지 않는 것은 아니다. 종종 활성화 함수를 사용하지 않는 층을 비선형 층들과 함께 인공 신경망의 일부로서 추가하는 경우도 있는데, 학습 가능한 가중치가 새로 생긴다는 점에서 의미가 있다. 예로 임베딩 층(embedding layer)의 경우 활성화 함수가 존재하지 않는다.
활성화 함수 종류
- 시그모이드 (Sigmoid):
- 출력 범위: 0에서 1 사이
- 이진 분류 문제의 출력층에서 사용
- 로지스틱 회귀(Logistic Regression)
- 하이퍼볼릭 탄젠트 (Tanh):
- 출력 범위: -1에서 1 사이
- 시그모이드 함수보다는 전반적으로 큰 값이 나와 기울기 소실 증상이 적은 편이며 은닉층에서 시그모이드 함수보다는 선호된다.
- 소프트맥스 (Softmax):
- 각 클래스에 대한 출력의 합이 1이 되도록 조정
- 다중 클래스 분류 문제의 출력층에서 사용
- 소프트맥스 회귀(Softmax Regression)
순전파(Forward Propagation) 와 역전파(BackPropagation)
순전파
아래의 그림은 두 개의 입력과 두 개의 은닉층 뉴런, 두 개의 출력층 뉴런을 사용하는 인공신경망이다. 은닉층과 출력층의 모든 뉴런은 활성화 함수로 시그모이드 함수를 사용한다.

순전파는 입력층에서 출력층으로 향한다.
- 은닉층 입력: 입력값 𝑥_1, 𝑥_2은 각각 가중치와 곱해지고, 가중합 𝑧_1, 𝑧_2는 은닉층 뉴런의 시그모이드 함수의 입력 값이 된다.
- 은닉층 통과: 𝑧_1과 𝑧_2는 각각의 은닉층 뉴런에서 시그모이드 함수를 지나고, 시그모이드 함수가 리턴하는 결과값 ℎ_1, ℎ_2는 은닉층 뉴런의 최종 출력값이 된다.
- 출력층 입력: ℎ_1, ℎ_2는 다시 각각의 값에 해당되는 가중치와 곱해지고, 가중합 3과 𝑧4 는 출력층 뉴런의 시그모이드 함수의 입력 값이 된다.
- 출력층 통과: 𝑧_3과 𝑧_4이 출력층 뉴런에서 시그모이드 함수를 지난 값은 이 인공 신경망이 최종적으로 계산한 출력값 (예측값) o1,o2 가 된다.
예측값과 실제값의 오차를 계산하기 위한 손실 함수를 선택하여 순전파를 통해 나온 예측값에 대한 각 오차를 모두 더하면, 전체 오차 𝐸_𝑡𝑜𝑡𝑎𝑙를 구할 수 있다. 회귀 문제에서는 MSE(Mean Squared Error), 분류 문제에서는 Cross-Entropy가 손실 함수로 흔히 사용된다.
역전파
위에서 언급했듯이 신경망 학습의 목표는 주로 비용 함수(손실 함수)를 최소화하는 것이다. 비용 함수를 최소화하는 매개 변수인 𝑤와 𝑏을 찾기 위한 작업을 수행하는 알고리즘을 옵티마이저 혹은 최적화 알고리즘이라고 했다. 역전파에서는 이 옵티마이저를 이용하여 가중치를 업데이트한다. 즉, 역전파는 신경망의 출력(예측)과 실제 값(타겟) 사이의 오차를 최소화하기 위해 사용된다.
아래의 예시의 경우 가장 기본적인 옵티마이저 알고리즘인 경사 하강법(Gradient Descent)을 사용한다고 가정한다. 때문에 비용함수를 미분하여 비용(손실) 최소화가 되는 지점, 접선의 기울기가 0인 곳을 향해 𝑤의 값을 변경하는 작업을 수행한다.

역전파는 반대로 출력층에서 입력층 방향으로 계산하면서 가중치를 업데이트한다. 출력층 바로 이전의 은닉층을 N층이라고 하였을 때, 출력층과 N층 사이의 가중치를 업데이트하는 단계를 역전파 1단계, 그리고 N층과 N층의 이전층 사이의 가중치를 업데이트 하는 단계를 역전파 2단계라고 해보자.
1단계

역전파 1단계에서 업데이트 해야 할 가중치는 𝑤5,𝑤6,𝑤7,𝑤8 총 4개다. 옵티마이저(경사 하강법) 수행을 위해 비용함수(손실함수) 의 결과인 전체 오차 𝐸𝑡𝑜𝑡𝑎𝑙를 각 가중치에 대해 편미분한다.

o1 = sigmoid(𝑧3), 𝑧3 = f(𝑤5) 라고 할 수 있으므로 연쇄 법칙(Chain rule)에 따라 편미분한다. 각 편미분 값을 구해 곱하고, 학습률(learning rate) 𝛼를 곱해 빼주면 업데이트된 가중치가 나온다. 이를 𝑤6,𝑤7,𝑤8 에 대해서도 수행해준다.
2단계

이제 입력층 방향으로 이동하며 다시 같은 방식으로 계산한다. 이번 단계에서 계산할 가중치는 𝑤1,𝑤2,𝑤3,𝑤4 이다.

마찬 가지로 옵티마이저 알고리즘에 따라 가중치를 구하여 업데이트한다. 자세한 내용은 여기 참고
정리하자면, 역전파는 오차를 기반으로 각 가중치가 오차에 얼마나 기여하는지를 계산하고, 비용 함수의 그래디언트(미분값)를 계산하여, 비용 함수가 최소가 되는 방향으로 가중치를 조정한다. 이러한 과정을 통해 신경망은 점점 더 정확한 예측을 할 수 있게 된다.
1. 데이터 전처리 (Preprocess)
인공지능을 학습시킬 때 데이터를 바로 입력하지 않는다.
1-1. 토크나이저(Tokenizer), 정수 인코딩(Integer encoding)
출처: https://wikidocs.net/31766 / https://wikidocs.net/21694 / https://wikidocs.net/32105
컴퓨터는 텍스트보다 숫자를 더 잘 처리할 수 있다. 때문에 자연어 처리할때 텍스트를 숫자로 매핑시켜 변경한다. 예를 들어 텍스트에 단어가 1000개가 있으면, 1번 단어부터 1000번 단어까지 고유한 정수(인덱스)를 부여한다(ex. love 는 100 번, apple 은 199번..). 이 인덱스를 부여하는 방법에는 여러가지가 있다.
이렇게 텍스트를 단어로 나누고(토큰화) 학습을 잘할 수 있는 형태로 변경하는 작업(정수 인코딩)을 하는 것을 토크나이저(Tokenizer)라고한다. 예로 케라스(keras)의 토크나이저(Tokenizer) 예를 보자.
from tensorflow.keras.preprocessing.text import Tokenizer
from tensorflow.keras.preprocessing.sequence import pad_sequences
tokenizer = Tokenizer()
train_text = "The earth is an awesome place live"
# 단어 집합 생성
tokenizer.fit_on_texts([train_text])
# 정수 인코딩
sub_text = "The earth is an great place live"
sequences = tokenizer.texts_to_sequences([sub_text])[0]
print("정수 인코딩 : ",sequences)
print("단어 집합 : ",tokenizer.word_index)정수 인코딩 : [1, 2, 3, 4, 6, 7]
단어 집합 : {'the': 1, 'earth': 2, 'is': 3, 'an': 4, 'awesome': 5, 'place': 6, 'live': 7}
케라스의 토크나이저는 텍스트 내 단어의 빈도수를 계산하여 가장 자주 등장하는 단어부터 순서대로 인덱스를 부여하는 정수 인코딩을 한다. 출력 결과를 보면 great는 학습했던 단어 집합(vocabulary)에 없어 출력되지 않았다.
1-2. 서브 워드 토크나이저 (Subword Tokenizer)
위와 같이 학습이 되지 않은 단어가 등장한 경우, 문제해결이 어려워 진다. 이를 OOV(Out-Of-Vocabulary) 문제라고 하며, OOV나 희귀 단어, 신조어와 같은 문제 완화를 위해 서브워드 토크나이저(Subword tokenizer)가 나왔다.
단어는 더 작은 단위의 의미있는 여러 서브워드들의 조합으로 구성된 경우가 많기 때문에, 하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩하겠다는 의도를 가진 전처리 작업이다. 즉, 기본적으로 자주 등장하는 단어는 그대로 단어 집합에 추가하지만, 자주 등장하지 않는 단어의 경우에는 더 작은 단위인 서브워드로 분리되어 서브워드들이 단어 집합에 추가된다. 예를 들어, 'unhappiness'를 'un', 'happi', 'ness'로 분할하여 언어의 더 깊은 구조적 특성을 얻을 수 있다.
서브 워드 토크나이저에는 BPE(Byte Pair Encoding), WordPiece, SentencePiece 등이 있다. 구글의 BERT의 경우 WordPiece 를 사용한다.
WordPiece
준비물 : 이미 훈련 데이터로부터 만들어진 단어 집합
1. 토큰이 단어 집합에 존재한다.
=> 해당 토큰을 분리하지 않는다.
2. 토큰이 단어 집합에 존재하지 않는다.
=> 해당 토큰을 서브워드로 분리한다.
=> 해당 토큰의 첫번째 서브워드를 제외한 나머지 서브워드들은 앞에 "##"를 붙인 것을 토큰으로 한다.BERT는 이미 위키피디아(25억 단어)와 BooksCorpus(8억 단어)와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다.
import pandas as pd
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained("bert-base-uncased") # Bert-base의 토크나이저
result = tokenizer.tokenize('Here is the sentence I want embeddings for.')
print(result)['here', 'is', 'the', 'sentence', 'i', 'want', 'em', '##bed', '##ding', '##s', 'for', '.']embeddings라는 단어는 단어 집합에 존재하지 않지만, 단어 em, ##bed, ##ing, ##s는 모두 단어 집합에 존재하게 된다.
2. 임베딩(Embedding)
임베딩은 주로 단어, 문장, 문서와 같은 텍스트 데이터를 고차원에서 저차원의 연속적인 벡터 공간으로 변환하는 방법을 말한다. 더 일반적인 용어로, 어떤 유형의 데이터(단어, 이미지, 소셜 네트워크의 노드 등)를 처리 가능한 형태, 특히 저차원의 밀집 벡터로 변환하는 기술을 포괄한다.
임베딩의 핵심 포인트
- 차원 축소: 임베딩은 일반적으로 매우 높은 차원의 데이터(예: 언어의 어휘)를 훨씬 낮은 차원의 공간으로 표현한다. 이렇게 함으로써 계산 효율성을 높이고, 데이터에서 중요한 패턴을 더 잘 추출할 수 있다.
- 의미적 유사성: 임베딩 과정에서는 비슷한 의미를 가진 단어나 문장이 벡터 공간에서 서로 가깝게 위치하도록 한다. 이는 코사인 유사도와 같은 기법을 사용하여 측정할 수 있다.
- 컨텍스트 인식: 최신 임베딩 기법(예: Word2Vec, GloVe, BERT의 문맥 기반 임베딩)은 단어의 주변 단어를 고려하여 단어의 의미를 파악한다. 이를 통해 같은 단어라도 다른 문맥에서 다른 의미를 가질 수 있음을 반영할 수 있다
출처: https://wikidocs.net/37001 / https://wikidocs.net/45609

데이터 사이언스 분야 한정으로 주로 3차원 이상의 배열을 텐서라고 부른다. 자연어 처리에서 특히 자주 보게 되는 것이 3D 텐서다. 3D 텐서는 시퀀스 데이터(sequence data)를 표현할 때 자주 사용된다. 여기서 시퀀스 데이터는 주로 단어의 시퀀스를 의미하며, 시퀀스는 주로 문장이나 문서, 뉴스 기사 등의 텍스트가 될 수 있다.

임베딩이 3D 텐서를 만드는 것과 관련하여, 심층 학습 모델, 특히 순환 신경망(RNN)이나 컨볼루션 신경망(CNN), 트랜스포머 모델에서 입력 데이터를 처리하기 위한 방법으로 사용된다.
3D 텐서의 구조: 일반적으로 [samples(배치 크기), timesteps(시퀀스 길이), word_dim(임베딩 차원)]으로 구성된다.
- 배치 크기: 한 번에 처리되는 데이터 샘플의 수
- 시퀀스 길이: 처리하는 각 샘플(예: 문장)의 단어 수.
- 임베딩 차원: 각 단어를 표현하는 벡터의 차원 수
3D 텐서를 보면 단어들이 벡터의 차원으로 표현되는 것을 알 수 있다. 임베딩 차원은 하이퍼파라미터로 모델의 성능에 영향을 주는 사람이 값을 지정하는 변수다. 예를 들어 단어가 10,000개가 있을때 사용자가 밀집 표현의 차원을 128로 설정한다면, 10,000개의 단어들은 차원은 128로 바뀌면서 모든 값이 실수가 된다. 이 경우 벡터의 차원이 조밀해졌다고 하여 밀집 벡터(dense vector) (혹은 임베딩 벡터(embedding vector))라고 하며, 단어를 밀집 벡터(dense vector)의 형태로 표현하는 방법을 워드 임베딩(word embedding)이라고 한다.
임베딩의 핵심 포인트에서 언급했듯이 워드 임베딩은 단어간 의미적 유사성을 파악할 수 있다.
'발표 자료를 살펴보다'와 '발표 자료를 톺아보다' 라는 두 가지 예문이 있다. '발표 자료를 살펴보다' 는 학습하여 단어 시퀀스가 존재하지만, '발표 자료를 톺아보다' 는 학습하지 않아 단어 시퀀스가 없는 언어 모델이 있다고 해보자. n-gram 언어 모델은 '살펴보다'와 '톺아보다'의 단어의 유사도를 알 수 없어 '발표 자료를' 다음에 '톺아보다'가 나올 확률을 0으로 연산해버린다.
만약 언어 모델이 의미적 유사성을 학습할 수 있도록 설계한다면, 훈련되지 않은 단어 시퀀스에 대한 예측이라도 유사한 단어가 사용된 단어 시퀀스를 참고하여 보다 정확한 예측을 할 수 있게 된다. 이러한 아이디어를 반영한 언어 모델이 신경망 언어 모델 NNLM이고, 워드 임베딩은 단어 벡터 간 유사도를 구할 수 있는 벡터를 얻어낼 수 있도록 한다.
단어를 밀집 벡터로 만드는 작업을 워드 임베딩이라고 하고, 밀집 벡터는 워드 임베딩 과정을 통해 나온 결과므로 임베딩 벡터라고도 한다고 했다. (밀집벡터 == 임베딩 벡터) 아래는 임베딩 벡터가 형성되는 단계를 설명한 그림이다.
어떤 단어 → 단어에 부여된 고유한 정수값 → 임베딩 층 통과 → 밀집 벡터

단어 great은 정수 인코딩 과정에서 1,918의 정수로 인코딩이 되었다. 단어 집합의 크기만큼의 행을 가지는 테이블(lookup table)에서 인덱스 1,918번에 위치한 행이 단어 great의 임베딩 벡터이며 모델의 입력이 된다.
즉, 임베딩 층은 룩업 테이블(lookup table)이라고 할수 있다. 임베딩 층의 입력으로 사용하기 위해서 입력 시퀀스의 각 단어들은 모두 정수 인코딩이 되어있어야 하며, 정수로 인코딩된 단어들은 임베딩층을 통과하면 임베딩 벡터를 얻을 수 있다.
이때 룩업 테이블은 각 단어 벡터를 그 단어의 의미적, 문맥적 특성을 고려하여 수치적으로 나타낸다. 즉, 비슷한 맥락에서 사용되는 단어들의 벡터는 서로 가깝게 위치하도록, 다른 맥락에서 사용되는 단어들은 서로 멀리 위치하도록 벡터값이 조정된다. 이 때문에 워드 임베딩으로 의미적 유사성을 파악할 수 있다고 한다.
피드 포워드 신경망 언어 모델(NNLM)
신경망 언어 모델의 시초인 피드 포워드 신경망 언어 모델을 살펴보자. NNLM이 언어 모델링을 학습하는 과정이다.
훈련 과정에서는 'what will the fat cat'이라는 단어 시퀀스가 입력으로 주어지면, 다음 단어 'sit'을 예측하는 방식으로 훈련된다. (원-핫 인코딩)
what = [1, 0, 0, 0, 0, 0, 0]
will = [0, 1, 0, 0, 0, 0, 0]
the = [0, 0, 1, 0, 0, 0, 0]
fat = [0, 0, 0, 1, 0, 0, 0]
cat = [0, 0, 0, 0, 1, 0, 0]
sit = [0, 0, 0, 0, 0, 1, 0]
on = [0, 0, 0, 0, 0, 0, 1]
1. 단어 정수 인코딩 및 워드 임베딩
윈도우 크기가 4인 경우로 앞 4단어만 본다.


룩업 테이블 후에는 V차원을 가지는 벡터 𝑥_{𝑓𝑎𝑡} 는 이보다 더 차원이 작은 M차원의 벡터 𝑒_{𝑓𝑎𝑡} 로 맵핑되었다. 이처럼 테이블 룩업을 통해 저차원으로 변경되었으므로 밀집벡터(임베딩 벡터)라고 할 수 있으며, 단어를 밀집 벡터로 표현하였으므로 워드 임베딩이다. 위의 설명이 이해됐다면 워드 임베딩을 통해 단어간 의미 유사성도 파악할 수 있음을 알 수 있다.
2. 각 임베딩 벡터 연결(concatenate)

각 단어가 테이블 룩업(임베딩 층)을 통해 임베딩 벡터로 변경되고, 투사층(projection layer)에서 모든 임베딩 벡터들의 값은 연결(concatenate)된다.
여기서 투사층이란, 인공 신경망에서 입력층과 출력층 사이의 층은 보통 은닉층이라고 부르는데, 투사층은 일반 은닉층과 다르게 가중치 행렬과의 곱셈은 이루어지지만 활성화 함수가 존재하지 않아 은닉층과 구분하기 위해 부르는 이름이다. 즉, 일반적인 은닉층이 활성화 함수를 사용하는 비선형층(nonlinear layer)인 것과는 달리 투사층은 활성화 함수가 존재하지 않는 선형층(linear layer)이라고 할 수있다.
3. 은닉층 통과
투사층의 결과는 h의 크기를 가지는 은닉층을 지난다. 은닉층을 지난다는 것은 가중치가 곱해진 후 편향이 더해져 활성화 함수의 입력이 된다는 의미다. 가중치와 편향을 𝑊_ℎ와 𝑏_ℎ이라고 하고, 은닉층의 활성화 함수를 하이퍼볼릭탄젠트 함수라고 하였을 때, 은닉층을 식으로 표현하면 아래와 같다. (p는 투사층으로 임베딩 백터가 연결된 값)

4. 출력층 통과

은닉층의 출력은 V의 크기를 가지는 출력층으로 향한다. 다시 또 다른 가중치와 곱해지고 편향이 더해지면, 입력이었던 원-핫 벡터들과 동일한 V차원의 벡터를 얻게 된다. (ex. 입력 벡터의 차원이 7이었다면 해당 벡터도 동일한 차원 수를 가짐) 출력층에서는 활성화 함수로 소프트맥스(softmax) 함수를 사용하는데, V차원의 벡터는 소프트맥스 함수를 지나면서 벡터의 각 원소는 0과 1사이의 실수값을 가지며 총 합은 1이 되는 상태로 바뀐다. 이 벡터를 NNLM의 예측값으로 𝑦^라고 할때 식으로 표현하면 아래와 같다.

𝑦^는 실제값. 즉, 실제 정답에 해당되는 단어 sit 의 원-핫 벡터의 값에 가까워져야 한다. 실제값에 해당되는 다음 단어를 𝑦라고 했을 때, 이 두 벡터가 가까워지게 하기 위해서 NNLM는 손실 함수로 크로스 엔트로피(cross-entropy)(소프트맥스 회귀의 비용 함수)를 사용한다.
학습을 하면서 실제 값과 예측값의 오차를 줄이기 위한 역전파가 이루어지면 모든 가중치 행렬들이 학습되는데, 여기에는 투사층에서의 가중치 행렬도 포함되므로 임베딩 벡터값 또한 학습된다.
NNLM의 핵심은 충분한 양의 단어들을 위와 같은 과정으로 훈련시킨다면, 여러 문장에서 유사한 목적으로 사용되는 단어들은 결국 유사한 임베딩 벡터값을 얻게되는 것에 있다. 이렇게 되면 훈련이 끝난 후 다음 단어를 예측 과정에서 훈련 단어 집합 없던 단어 시퀀스라 하더라도 다음 단어를 선택할 수 있다. 그러나 NNLM의 경우 다음 단어를 예측하기 위해 모든 이전 단어를 참고하는 것이 아니라 정해진 n개의 단어만을 참고할 수 있다는 한계도 존재한다.
3. 트랜스포머 (Transformer) - 인코더(Encoder)
https://wikidocs.net/22886 / https://wikidocs.net/22888 를 통해 RNN 에 대한 이해를 한후 BERT를 보는 것을 추천한다.
3-1. RNNM (Recurrent Neural Network Language Model)
출처: https://wikidocs.net/46496
n-gram 과 NNLM 모두 입력 길이 제한이 있다는 한계가 있었다. RNNM의 핵심은 시점(time step)이라는 개념이 도입하여 입력의 길이를 고정하지 않을 수 있다는 점이다.

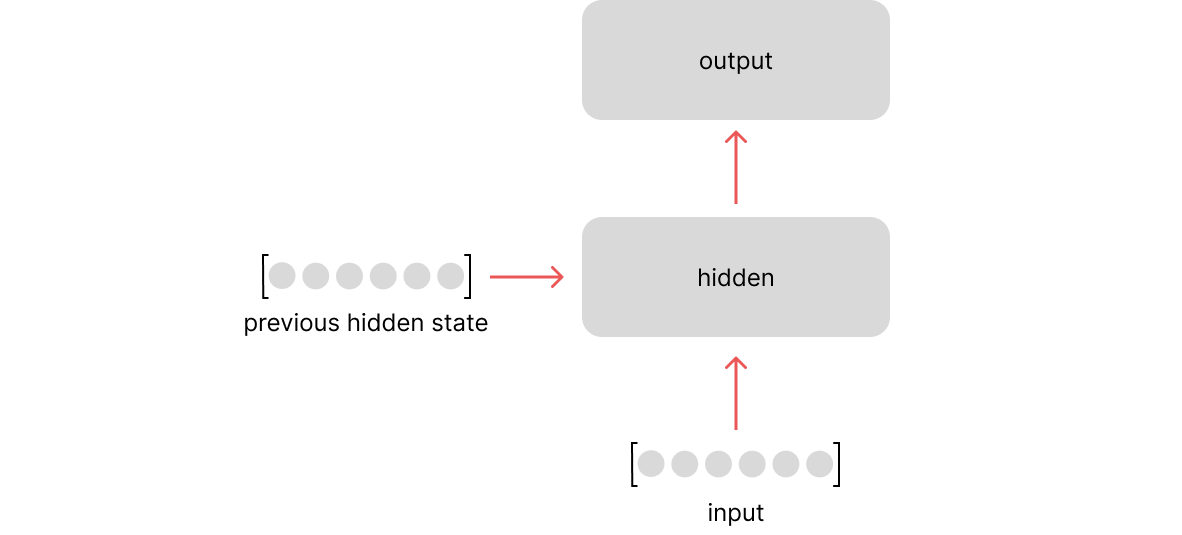
위의 그림은 훈련이 끝난 RNNM이 테스트 과정시(실제 사용시) 동작하는 모습이다. 이전 시점의 출력을 현재 시점의 입력으로 사용한다. 훈련시에는 교사 강요(teacher forcing)를 사용한다. 교사강요는 위의 그림과 달리 이전 시점에서의 출력(예측한 값)을 현재 시점의 입력으로 사용하지 않고 현재 시점의 정답(실제 값)을 입력으로 사용한다. (한 번 잘못 예측하면 뒤에서의 예측까지 영향을 미쳐 훈련 시간이 느려지기 때문)
1. 단어 정수 인코딩 및 워드 임베딩 / 2. 각 임베딩 벡터 연결(concatenate)

NNLM을 이해했다면 위의 그림은 이해하기 쉬울 것이다. 마찬가지로 임베딩 층(룩업 테이블)을 거쳐 임베딩 벡터를 얻는다.
3. 은닉층 통과


NNLM 과 달리 은닉층에서 t 시점의 x 값에 대한 임베딩 벡터와 함께 이전 시점의 은닉 상태인 ℎ_{𝑡−1}를 이용하여 현재 시점의 은닉 상태 ℎ_𝑡를 계산한다. 그뒤는 NNLM 과 유사하다.
4. 출력층 통과
은닉층에서 나온 결과를 소프트맥스 함수를 사용하여 벡터의 각 원소는 0과 1사이의 실수값으로 나타낸다.

마찬가지로 𝑦_𝑡^는 실제값으로, 실제 정답에 해당되는 단어 벡터값에 가까워져야 한다. 이 두 벡터가 가까워지게 하기 위해 RNNLM는 손실 함수로 cross-entropy 함수를 사용하고, RNNLM 역시 실제 값과 예측값의 오차를 줄이기 위한 역전파로 가중치 행렬과 임베딩 벡터를 학습시킨다.
3-2. 어텐션 (Attention)
트랜스포머 모델의 핵심은 "셀프 어텐션(Self-Attention)"이라는 방식을 사용한다는 점이다. 어텐션에 대해 알아보자
출처: https://wikidocs.net/22893
어텐션의 기본 아이디어는 디코더에서 출력 단어를 예측하는 매 시점(time step)마다 인코더에서의 전체 입력 문장을 다시 한 번 참고한다는 점이다. 이때 전체 입력 문장을 전부 다 동일한 비율로 참고하는 것이 아니라, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 보도록한다.

어텐션 메커니즘의 세 가지 주요 구성 요소: 쿼리(Queries), 키(Keys), 값(Values)
Attention(Q, K, V) = Attention Value
이 세 요소는 모델이 어디에 주목해야 할지 결정하는 데 사용된다.
- 쿼리(Query): 현재 처리 중인 입력 또는 상태 (t 시점의 디코더 셀에서의 은닉 상태)
- 키(Key): 비교 대상이 되는 다른 입력들의 요소 (모든 시점의 인코더 셀의 은닉 상태들)
- 값(Value): 키와 연관된 실제 정보로, 어텐션 가중치가 적용될 대상 (모든 시점의 인코더 셀의 은닉 상태들)
다음은 닷-프로덕트 어텐션(Dot-Product Attention) 이다.

어떻게 단어와 연관있는 부분을 집중해서 보도록 하는 것일까? 소프트 맥스의 함수 출력은 I, am, a, student 단어 각각이 출력 단어를 예측할 때 얼마나 도움이 되는지의 정도를 수치화한 값이다. 이를 하나의 정보로 담아서 디코더로 전송한다.(위의 그림에서는 초록색 삼각형) 이로인해 디코더는 중요한 부분을 좀더 집중하여 참고해 출력 단어를 더 정확하게 예측할 확률이 높아진다.
- ℎ_1, ℎ_2, ... ℎ_𝑁: 인코더의 시점(time step)을 각각 1, 2, ... N이라고 하였을 때 인코더의 은닉 상태(hidden state)
- 𝑠_𝑡: 디코더의 현재 시점 t에서의 디코더의 은닉 상태(hidden state)
닷-프로덕트 어텐션 계산 과정은 아래와 같다.
어텐션 스코어(Attention Score) -> 어텐션 분포(Attention Distribution) -> 어텐션 값(Attention Value) -> 어텐션과 𝑠𝑡 연결(𝑣𝑡)
- 어텐션 스코어:
- 스코어 계산시 내적을 사용하여 닷-프로덕트 어텐션이라고 한다.
- 𝑠_𝑡(Query)의 전치 행렬은 인코더의 입력의 각 은닉 상태(Key)와 내적하여 𝑒^𝑡를 얻을 수 있다.
- Q 와 나머지 값을 내적하여 어느 단어가 다른 단어보다 더 중요한지 계산한다.
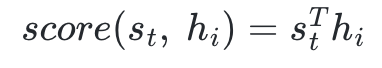

- 어텐션 분포:
- 𝑒^𝑡에 소프트맥스 함수를 적용하면, 모든 값을 합하면 1이 되는 확률 분포를 얻을 수 있다.
- 이 값은 어텐션 가중치(Attention Weight)이며, 출력하는 현재 시점 t에서의 은닉상태에 대한 각 입력 값의 중요정도라고 볼 수 있다.

- 어텐션 값:
- 구해진 각 가중치를 각 인코더의 은닉 상태(Value)에 반영해준다. (가중합(Weighted Sum))
- 어텐션 값을 컨텍스트 벡터(context vector) 라고 부르기도 한다.


- 어텐션과 𝑠_𝑡 연결:
- 최종값인 어텐션 값 𝑎𝑡를 𝑠_𝑡와 결합(concatenate)하여 하나의 벡터로 만드는 작업을 수행한다.
- 연결된 벡터가 𝑣_𝑡일때, 𝑣_𝑡를 𝑦^ 예측 연산의 입력으로 사용하므로서 인코더로부터 얻은 정보를 활용하여 𝑦^(예측값)를 좀 더 잘 예측할 수 있게 된다.

최종적으로 𝑣𝑡는 출력층의 입력으로 들어가 예측 벡터를 얻는다.
정리하자면, 어텐션 함수는 쿼리(𝑠_𝑡) 에 키(ℎ_1, ℎ_2, ... ℎ_𝑁)를 곱하여 나온 쿼리에 대한 모든 키의 유사도(어텐션 가중치)를 키와 맵핑되어있는 각각의 값(ℎ_1, ℎ_2, ... ℎ_𝑁)에 반영(가중합)해준다.

3-3. 트랜스포머 (Transformer)
모델은 RNN이 아닌, ‘어텐션(Attention)’만으로 같은 인코더-디코더 구조를 구축한 모델이다.
포지셔널 인코딩(Positional Encoding)
출처: https://wikidocs.net/31379
트랜스포머가 모든 입력을 한 번에 처리할 수 있는 "병렬 처리" 구조를 가지고 있어 시퀀스 순서대로가 아닌, 시퀀스의 각 요소를 독립적으로 처리한다. 이러한 한계를 극복하기 위해 트랜스포머는 포지셔널 인코딩을 도입한다. 연속적인 인덱스 등을 사용하여 위치를 나타낼수 있지만 그러면 포지션 값이 너무 커지게 된다는 문제가 있다.
포지셔널 인코딩은 각 입력 요소에 고유한 위치 정보를 추가하여, 모델이 시퀀스의 순서 정보를 인식하고 활용할 수 있도록 한다. 이를 통해 트랜스포머는 문장의 문법적 구조와 의미적 맥락을 더 잘 파악할 수 있다.



트랜스포머의 인코더와 디코더는 단순히 각 단어의 임베딩 벡터들을 입력받는 것이 아니라, 위와 같이 임베딩 벡터가 모여 만들어진 문장 행렬과 포지셔널 인코딩 행렬의 덧셈 연산을 통해 조정된 값을 입력받는다. 자세한 내용은 포지션 인코딩에 대해 잘 설명되어 있는 글이 있어 넘어간다.
셀프 어텐션(Self-Attention)
3-2 에서 설명한 어텐션과 유사하지만 몇 가지 다른점이 있다.
1. Q(query), K(key), V(value) 가 모두 같은 값으로부터 나온다.
- 위에서 설명한 어텐션은 디코더 셀의 은닉 상태가 Q이고 인코더 셀의 은닉 상태가 K라는 점에서 Q와 K가 서로 다른 값을 갖는 반면, 셀프 어텐션은 쿼리, 키, 값 모두 입력 문장의 모든 단어 벡터들이다

문장 행렬에 가중치 행렬을 곱하여 Q행렬, K행렬, V행렬을 구한다. 각 가중치 행렬은 𝑑_𝑚𝑜𝑑𝑒𝑙×(𝑑_𝑚𝑜𝑑𝑒𝑙/num_heads)의 크기를 갖는다.
- 𝑑_𝑚𝑜𝑑𝑒𝑙: 하이퍼파라미터로 트랜스포머의 인코더와 디코더에서의 정해진 입력과 출력의 크기, 임베딩 벡터의 차원을 의미
- num_heads: 하이퍼파라미터로 트랜스포머 모델에서 인코더와 디코더가 총 몇 층으로 구성되었는지를 의미
2. 𝑠𝑐𝑜𝑟𝑒(𝑞,𝑘)=𝑞⋅𝑘가 아니라 여기에 특정값으로 나눠준 어텐션 함수인 𝑠𝑐𝑜𝑟𝑒(𝑞,𝑘)=𝑞⋅𝑘/𝑛를 사용한다.
- 이 어텐션 함수를 스케일드 닷-프로덕트 어텐션(Scaled dot-product Attention) 라고 한다.

나눠주는 이유에 대해서는 이 글에서 잘 설명 되어있다.
따라서 어텐션 스코어는 아래의 내적 결과 행렬을 √𝑑𝑘 로 나눠주어 어텐션 스코어를 구한다. 여기서 𝑑𝑘 는 𝑑_𝑚𝑜𝑑𝑒𝑙/num_heads 다.
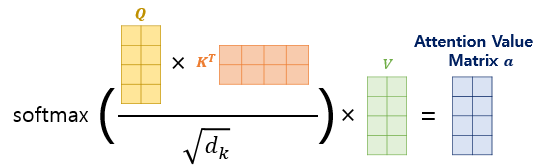
셀프어텐션의 경우 로 √𝑑𝑘로 나눠준 것이 어텐션 스코어이기 때문에 이를 softmax함수에 넣어주고 value와 곱하여 어텐션 값을 구한다. (Q벡터와 K벡터의 차원을 𝑑_𝑘, V벡터의 차원을 𝑑_𝑣로 가르킴, 그림에서는 𝑑𝑘와 𝑑𝑣의 차원은 𝑑𝑚𝑜𝑑𝑒𝑙/num_heads와 같음 )


멀티 헤드 어텐션(Multi-head Attention)

𝑑_𝑚𝑜𝑑𝑒𝑙의 차원이 아닌 축소하여 사용하는 이유는 트랜스 포머가 num_heads 개만큼 병렬처리를 하기 때문이다. 즉, 설명한 어텐션이 num_heads 개로 병렬로 이루어지게 되는데, 이때 각각의 어텐션 값 행렬을 어텐션 헤드라고 부른다. 이때 가중치 행렬 𝑊_𝑄,𝑊_𝐾,𝑊_𝑉의 값은 num_heads개의 어텐션 헤드마다 전부 다르다.
어텐션 헤드

어텐션 헤드를 모두 연결한 행렬은 또 다른 가중치 행렬 𝑊𝑜을 곱하게 되는데, 이렇게 나온 결과 행렬이 멀티-헤드 어텐션의 최종 결과물이며, 결과물인 멀티-헤드 어텐션 행렬은 인코더의 입력이었던 문장 행렬의 (L, 𝑑𝑚𝑜𝑑𝑒𝑙) 크기와 동일하다.
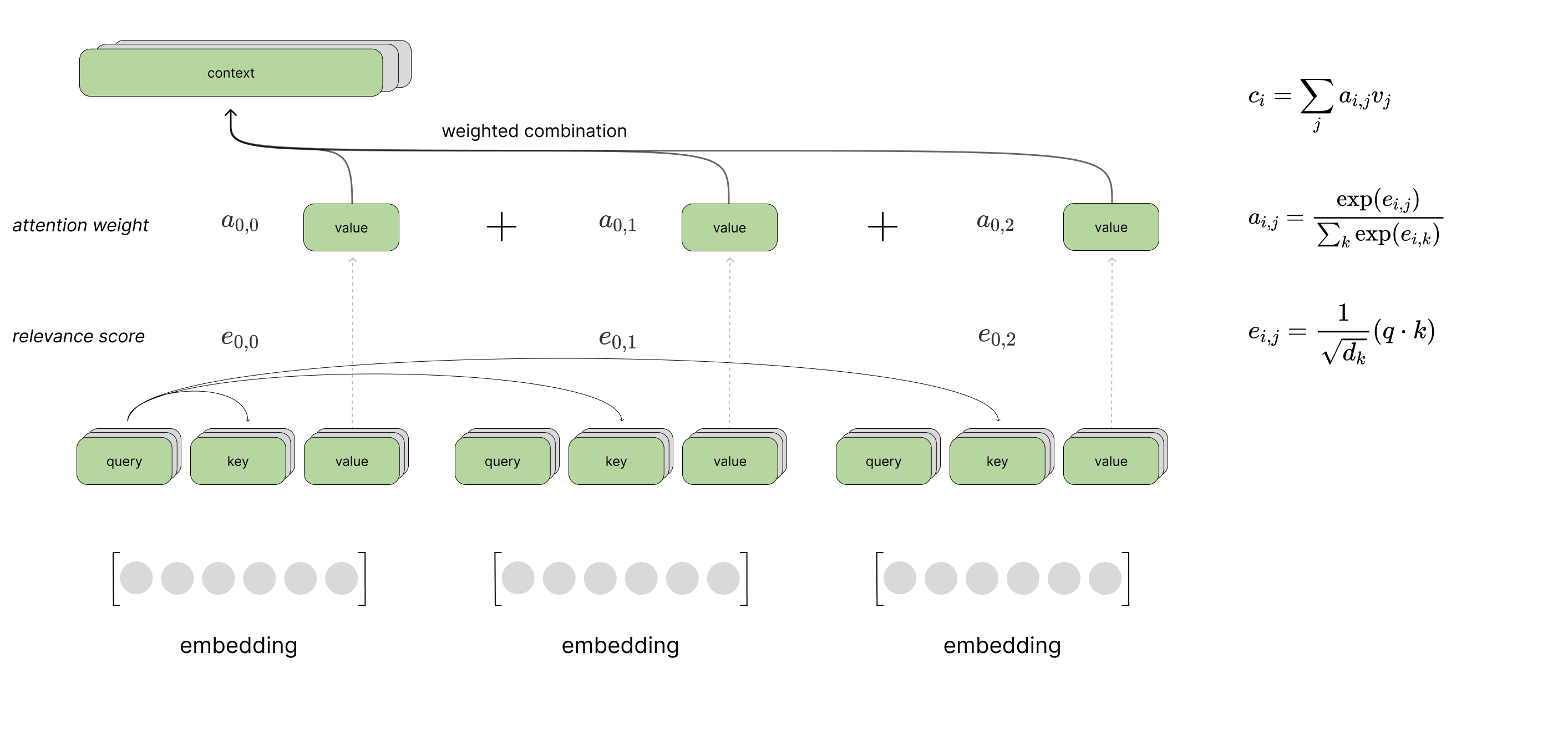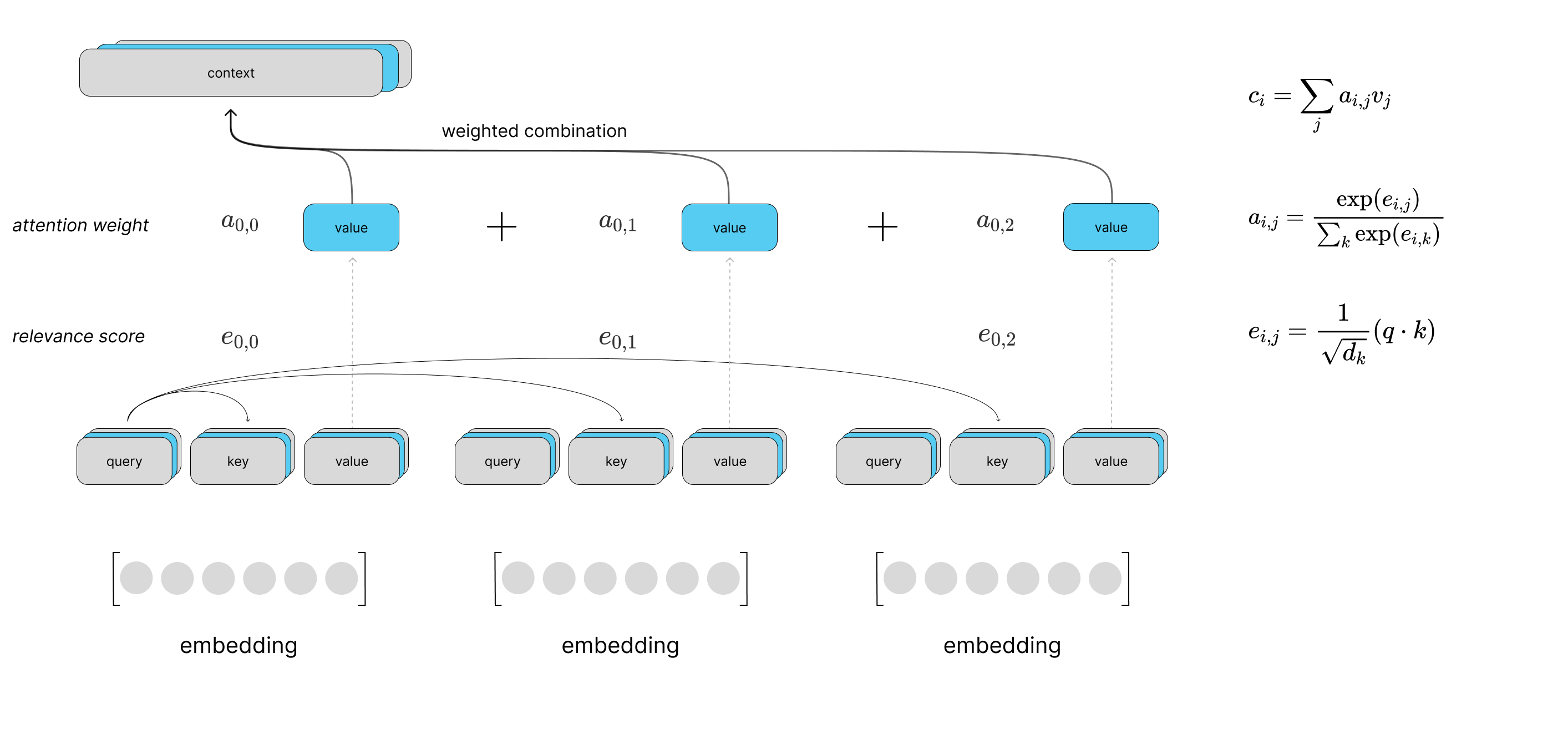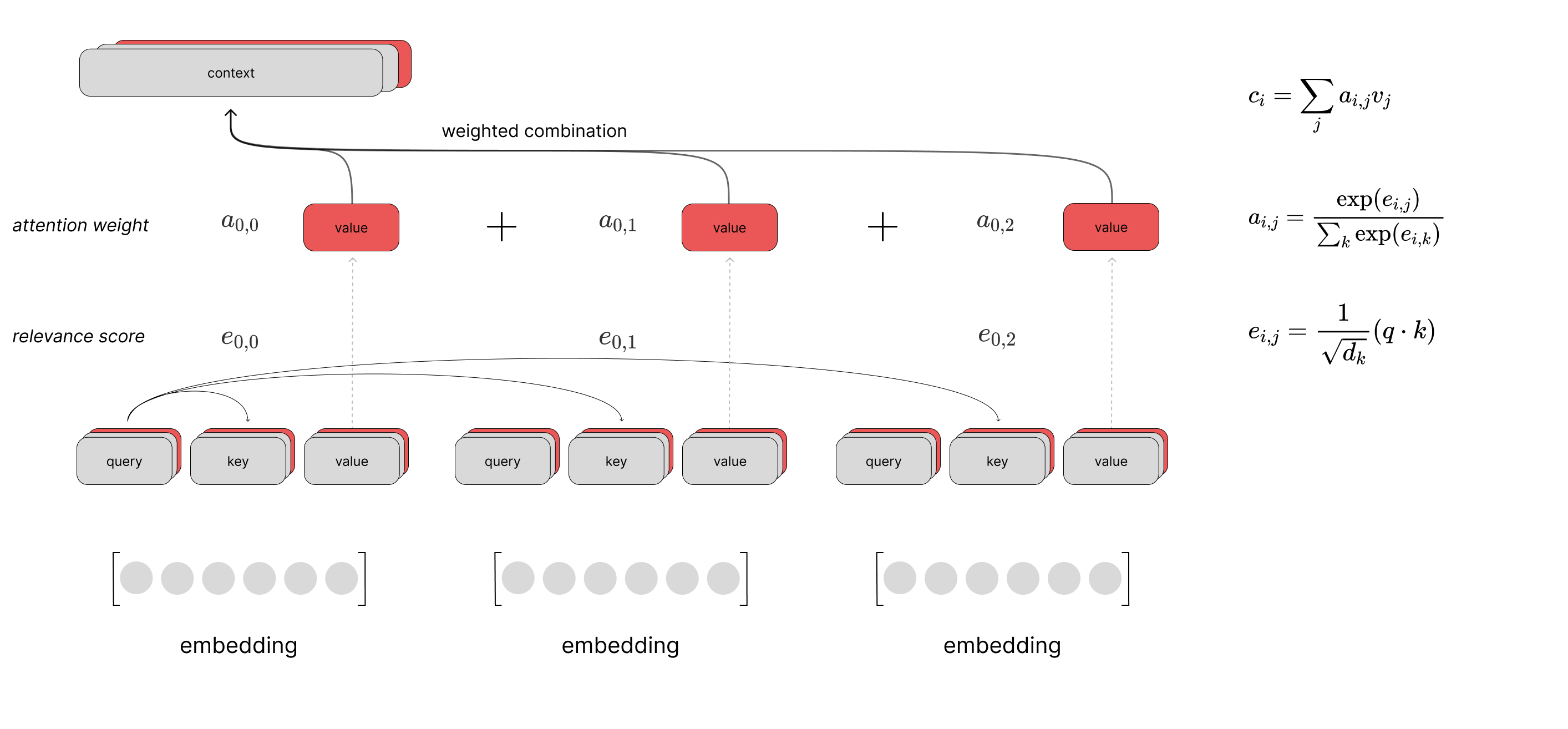
잔차 연결(Residual connection)과 층 정규화(Layer Normalization)
멀티 헤드 어텐션 결과 값은 잔차 연결, 층 정규화 후 포지션-와이즈 피드 포워드 신경망(Position-wise FFNN)을 통과한다.

- 잔차 연결:
- 잔차 연결은 서브층의 입력과 출력을 더하는 것을 말한다.

- 층 정규화:
- 층 정규화는 텐서의 마지막 차원에 대해서 평균과 분산을 구하고, 이를 가지고 어떤 수식을 통해 값을 정규화하여 학습을 돕는 것이다.
- 여기서 텐서의 마지막 차원이란 것은 트랜스포머에서는 𝑑_𝑚𝑜𝑑𝑒𝑙 차원을 의미한다.
4. BERT
출처: https://wikidocs.net/208933 / https://wikidocs.net/115055
이제 거의 다왔다. 위에서 설명한 내용들로 BERT 를 구성할 수 있다.

BERT는 트랜스포머의 인코더 부분으로 만들어졌으며, 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다.
이때 인코더 부분에 해당하는 BERT는 텍스트를 요약하거나 분류하는 등의 자연어 이해(Natural Language Understanding, NLU) 작업에 특화되어 있고, 디코더 부분에 해당하는 GPT는 문장 생성 등 자연어 생성(Natural Language Generation, NLG)에 특화되어 있다고 볼 수 있다.
4-1. BERT 크기


- layer(L): 트랜스포머 인코더 층의 수
- dimension(H): 임베딩 벡터 차원 (𝑑_𝑚𝑜𝑑𝑒𝑙)
- attension head(A): 셀프 어텐션 헤드의 수
4-2. 문맥을 반영한 임베딩(Contextual Embedding)
이는 워드 임베딩에서 설명한 것과 같다.
BERT의 입력은 임베딩 층(Embedding layer)를 지난 임베딩 벡터들이다. BERT base의 경우 hidden size 가 768이므로 모든 단어들은 768차원의 임베딩 벡터가 되어 BERT의 입력으로 사용된다
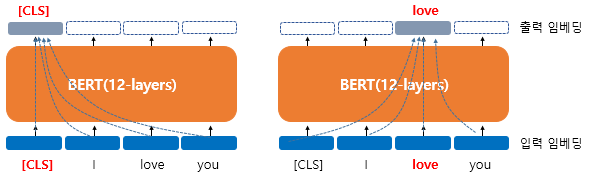
위의 그림은 한 단어를 출력할 때 문장의 문맥을 모두 참고하여 반영한 임베딩이 됨을 설명하는 그림이다.
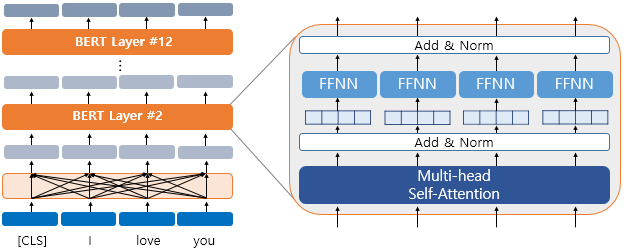
BERT는 트랜스포머 인코더를 여러층 쌓은 것이므로 첫번째 층의 출력 임베딩은 BERT의 두번째 층에서는 입력 임베딩이 된다. 또한 내부적으로 각 층마다 멀티 헤드 셀프 어텐션과 포지션 와이즈 피드 포워드 신경망을 수행한다.
4-3. 포지션 임베딩(Position Embedding)
트랜스포머에서는 사인 함수와 코사인 함수를 사용하여 위치에 따라 다른 값을 가지는 행렬을 만들어 이를 단어 벡터들과 더해 위치 정보를 표현하는 포지셔널 인코딩(Positional Encoding)을 사용했다. 이와 유사하지만, BERT에서는 학습을 통해서 얻는 포지션 임베딩(Position Embedding)이라는 방법을 사용한다.

문장의 길이가 4라면 4개의 포지션 임베딩 벡터를 학습키는 것이다. 제 BERT에서는 문장의 최대 길이를 512로 하고 있으므로, 최대 총 512개의 포지션 임베딩 벡터가 학습된다.
4-4. 세그먼트 임베딩(Segment Embedding)
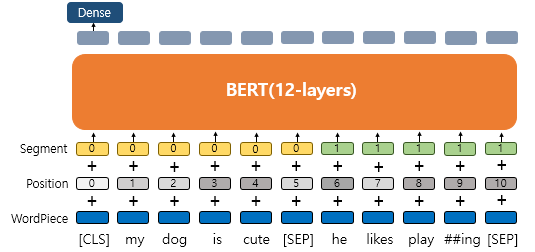
두 개의 문장 입력을 처리할때 사용되는 층이다. 각 문장들을 구분하기 위해 첫번째 문장에는 0 임베딩, 두번째 문장에는 1 임베딩을 더해주는 방식으로 간단하다.

BERT는 총 3개의 임베딩이 존재한다.
- WordPiece Embedding : 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개(사전 학습된 언어의 크기).
- Position Embedding : 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개.
- Segment Embedding : 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개.
4-5. BERT의 사전 훈련(Pre-training)
BERT 는 두가지 사전훈련 방식으로 학습되었다.
마스크드 언어 모델(Masked Language Model, MLM)

인공 신경망의 입력으로 들어가는 입력 텍스트의 15%의 단어를 위와 같이 랜덤으로 마스킹(Masking)한 후 인공 신경망에게 이 가려진 단어들을(Masked words) 예측하도록 한다. 15%의 선택된 단어 중 80%가 [MASK] 토큰으로 교환된다. 10%의 단어는 다른 단어로 교환되고 10%는 변경되지 않는다.
다음 문장 예측(Next Sentence Prediction, NSP)
문장 간의 관계를 포착하는 것을 목표로 한다. 두 개의 문장을 준 후에 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련한다. 이를 위해서 50:50 비율로 실제 이어지는 두 개의 문장과 랜덤으로 이어붙인 두 개의 문장을 주고 훈련시킨다.

BERT의 입력으로 넣을 때에는 [SEP]라는 특별 토큰을 사용해서 문장을 구분한다. 자세한 내용은 여기서 확인
5. BERT로 데이터 전처리 해보기
자연어를 처리할때 텍스트를 토큰화하고 정수 인코딩한다고 했다. 이때 언어별로 문장 구조 등이 다르기 때문에 각 언어에 특화된 BERT 모델을 쓰는 것이 적절하다.
토큰화
bert-base-uncased
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
input_word_ids = text_preprocessed['input_word_ids'].numpy()
tokens = tokenizer.convert_ids_to_tokens(input_word_ids[0])
print(tokens)['[CLS]', 'ᄂ', '##ᅥ', '##ᆫ', 'ᄂ', '##ᅮ', '##ᄀ', '##ᅮ', '##ᄂ', '##ᅵ', '[SEP]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]', '[PAD]']
KoBERT
tokens = tokenizer.convert_ids_to_tokens(tokenizer.encode(trainfeatures.iloc[0, 0]))
print(tokens)['[CLS]', '▁', '넌', '▁누구', '니', '[SEP]']
두 BERT는 모두 "넌 누구니" 라는 문장을 입력받았다. 출력결과를 보면 알 수 있듯이 일반 모델은 모음과 자음을 분리하여 토큰화 했지만, KoBERT의 경우에는 적절히 문장을 토큰화 했음을 알 수 있다.
정수 인코딩
정수 인코딩 값 역시 BERT 모델 마다 다르다.
bert-base-uncased
text_test = trainfeatures[0]
text_preprocessed = bert_preprocess_model(text_test)
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')Word Ids : [ 101 1456 30008 30021 1456 30014 29991 30014 29992 30019 102 0]
KoBERT
trainfeatures=train_df.copy()
tokenizer.encode(trainfeatures.iloc[0, 0])[2, 517, 5695, 1528, 5770, 3]이는 KoBERT를 이용해 같은 문장을 정수화한 결과다. 이는 모델에 등록된(학습된)단어들로 표현됨을 알 수 있다.
단어별 정수 인코딩 값은 다음 함수 실행을 통해 알 수 있다
vocab_dict = tokenizer.get_vocab()
vocab_dict["안"]6812
이제 BERT에 풀고자 하는 태스크의 데이터를 추가로 학습 시켜서 테스트 해야한다.
BERT 를 이용해 추가 학습을 시키는 파인튜닝 (Fine-tunning)단계는 다음 글에서 진행해보려고한다.