Tour of Computer System
각 컴퓨터 시스템에 대한 자세한 내용은 추후 다를 예정이며, 본 글에서는 전체적인 구조 정리를 목표로 한다.
Hardware Organiztion of a System

Bues
- Collection of electrical conduits
버스는 컴포넌트 사이에 정보 바이트를 왔다갔다 하며 운반한다. 보통 word 사이즈의 고정 크기를 전송하며, 4bytes(32-bit) 혹은 8bytes(64-bit)다.
I/O Devices
- The system's connection to the external world
유저 인풋을 위한 디바이스(마우스, 키보드)와 유저 아웃 풋을 위한 디바이스(디스플레이), 디스크. I/O 디바이스는 컨트롤러(controller)나 어댑터(adapter) 에 의해 I/O 버스와 연결된다.
Main Memory
- Temporary storage device
프로세서가 프로그램을 실행하는 동안 프로그램과 데이터를 hold 한다. 물리적으로 메인 메모리는 Dynamic Random Access Memory(DRAM)으로 이루어져 있다. 로직적으로는 각 0부터 시작하는 유니크한 주소를 가진 바이트의 선영 배열로 구성되어 있다. 프로세서는 하드 디스크에 직접 접근할 수 없으므로 메인 메모리에 올려서 접근한다.
Proccessor
- The Central Processing Unit(CPU)
메인 메모리에 저장된 instruction을 해석 혹은 실행하는 엔진이다. 코어에는 Program Counter(PC)라고 불리는 word-size 의 스토리지 디바이스(혹은 레지스터) 가 있다. PC는 메인 메모리에서 어떤 기계어(machine-language) 명령어(instruction)의 주소를 가리킨다.
전원이 켜지고 꺼질때 까지, 프로세서는 반복적으로 PC가 가리키고 있는 명령어를 실행하고, PC는 다음 명령어를 가리키도록 업데이트 한다. 프로세서는 Instruction Set Architecture(ISA) 모델을 따른다. ISA는 하드웨어와 소프트웨어 사이의 Interface로 하드웨어와 소프트웨어를 연결해준다.
(1) 프로세서는 메모리로 부터 PC가 가르키고 있는 명령어를 읽고 (2) 명령어 내 비트(bits)를 해석하고, (3) 명령어에 의해 지시된 간단한 작업을 수행한다. 그리고 나서 (4) 다음 명렁어로 PC가 가리키는 곳을 업데이트 한다.
프로세서는 메인 메모리, 레지스터 파일, Arithmetic/Logic Unit(ALU)를 선회한다. 레지스터 파일(register file)은 word-size 레지스터들로 구성된 작은 스토리지 디바이스다. 각각은 유니크한 이름을 가진다. ALU는 새 데이터와 주소 값을 계산한다. CPU가 명령어에 따라 수행할 수 있는 간단한 작업의 예시는 다음과 같다.
- Load: 이전 레지스터 내용을 덮어쓰면서, byte 나 word 를 메인 메모리에서 레지스터로 복사한다.
- Store: 해당 위치의 이전 내용을 덮어쓰면서, byte 나 word 를 레지스터에서 메인 메모리로 복사한다.
- Operate: 이전 레지스터 내용을 덮어쓰면서, 두 레지스터 내용을 ALU에 복사하고 산술 작업을 수행하여 결과를 레지스터에 저장한다.
- Jump: 이전 PC값을 덮어쓰면서, 명령어로부터 word를 가져와 PC에 복사한다.
실제로 프로세서는 프로그램 실행 속도를 높이기 위해 훨씬 더 복잡한 메커니즘을 사용한다. 그러므로 우리는 각 기계 코드 명령의 효과를 설명하는 프로세서의 ISA와 프로세서가 실제로 구현되는 방법을 설명하는 마이크로 아키텍처(microarchitecture)를 구별할 수 있다. ISA는 소프트웨어 개발자에게 프로세서의 동작을 알려주는 인터페이스 역할을 하며, 마이크로아키텍처는 하드웨어 엔지니어에게 실제로 그 동작을 어떻게 수행하는지를 알려주는 것으로 ISA를 이해하고 명령어의 의도대로 실행되는 CPU 내부의 하드웨어 구조이다.예를 들어, 같은 ISA를 가진 두 프로세서라도 각각의 마이크로아키텍처는 다를 수 있다.
이제 자세히는 아니지만, 프로그램 실행시 어떤 일이 일어나는지 전체적으로 알 수 있다.

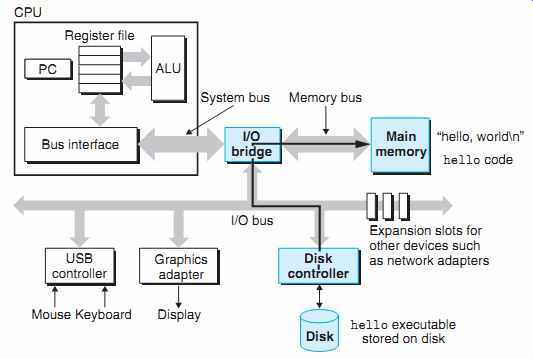
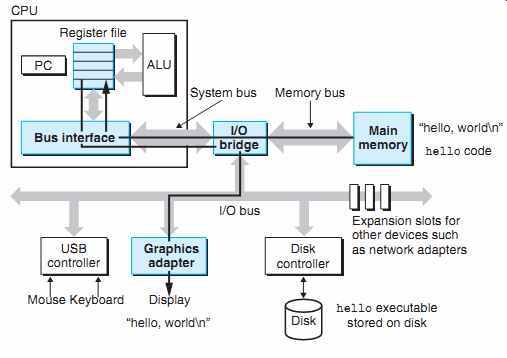
Cache Matter
시스템은 정보를 한쪽에서 다른 쪽으로 옮길때 많은 시간을 소비한다. 프로그램 내 에 있는 기계 명령어는 초기에 디스크에 저장된다. 프로그램이 로드되면 메인 메모리로 복사된다. 프로세서가 프로그램을 실행하기 때문에, 명령어는 메인메모리에서 프로세서로 복사된다.
비슷하게, 데이터 스트링 "hello, world\n" 은 초기에 디스크에 저장되었다가 메인 메모리로 복사 된 후 메인 메모리에서 디스플레이 디바이스로 복사된다. 이러한 여러번의 복사는 프로그램을 느리게 만드는 오버헤드, 때문에 시스템 디자인의 주요 목표는 복사 작업을 가능한 빠르게 만드는 것이다.
processor-memory gap
물리적 법칙에 따라 일반적으로 더 큰 스토리지 디바이스는 작은 스토리지 디바이스보다 느리고, 빠른 디바이스는 느린 디바이스보다 더 비싸다. 예를 들어, 일반적으로 디스크 드라이브가 메인 메모리 보다 1,000배 크지만, 프로세서가 word 를 읽을때 메인 메모리리에서 읽어오는 것 보다 디스크에서 읽어오는 것이 10,000,000 배 오래걸린다. 비슷한 예로 전형적인 레지스터 파일은 주 메모리의 수십 바이트에 비해 몇 백 바이트의 정보만을 저장한다. 그러나 프로세서는 메모리에서 읽어오는 것 보다 레지스터에서 데이터를 읽어오는 것이 거의 100 배 빠르다.
(프로세서가 데이터 읽어오는 속도: register file > memory > disk, 데이터 저장할수 있는 크기: disk > memory > register file)


이러한 문제를 해결하기 위해 더 작고 빠른 스트리지 디바이스 cache memory (cache, 캐시) 를 포함했다. 캐시는 프로세서가 가까운 미래에 필요할 것 같은 정보를 staging하는 임의의 공간이다. 캐시에는 자주 사용되는 데이터가 보관되는 반면, 메인 메모리(RAM)는 현재 실행 중인 데이터를 보관한다. 캐시는 메모리보다 훨씬 빠르고 비싸다.

- L1 캐시 – L1 캐시는 일반적으로 프로세서에 내장되어 있으며, 레지스터 파일과 비슷한 속도로 접근할 수 있다.
- L2 캐시 – L2 캐시는 L1보다 비교적 크고 느리다. L2는 프로세서 또는 별도의 칩에 구현된다. 프로세서는 특별한 버스(bus)로 L2 캐시에 직접 액세스할 수 있다. 프로세서가 액세스 할때 L1 캐시보다 5배 정도 오래 걸리지만, 메인 메모리 액세스 보다는 5~10배정도 빠르다.
- L3 캐시 – L3는 위 두 캐시의 성능을 향상시키기 위해 구현되었다. L3 캐시는 멀티코어 프로세서 외부에 존재하며 프로세서의 각 코어는 L3 캐시를 공유할 수 있다. L1, L2보다는 느리지만 메인 메모리보다는 빠르다.
L1 및 L2 캐시는 정적 랜덤 액세스 메모리(Static Random Access Memory, SRAM) 라는 하드웨어 기술로 구현된다. 캐시와 레지스터는 CPU 내부에 있으므로 접근 속도가 메모리보다 빠르다.
Memory hierachy

위에서 아래로 내려올 수록 디바이스는 더 느리고 더 커지고 비트당 더 저렴해 진다.
레지스터 파일은 제일 위에 위치하며, level 0 혹은 L0으로 알려져있다. 메모리 계층 구조의 메인 아이디어는 한 레벨은 다음 레벨의 스토리지 역할을 한다는 것이다. 레지시트 퍼알은 L1의 캐시 이고, L1은 L2의 캐시이고 L2는 L3의 캐시이다. L3는 메인메모리에 대한 캐시이다.
Operating System Manages the Hardware

쉘이 로드되면, 프로그램을 실행하고 프로그램이 메세지에 프린트 될때 프로그램은 키보드, 디스플레이, 디스크, 혹은 메인 메모리에 직접적으로 접근하지 않는다. 프로그램의 하드웨어 접근은 Operating System(OS) 에 의존한다. 애플리케이션 프로그램과 하드웨어 사이에 소프트웨어 레이어로써 운영체제가 있다고 생각하면된다. 프로그램이 하드웨어를 조작하려면 운영체제를 통해야한다.
운영체제는 두 가지 주요 목적이 있다. (1) 애플리케이션에 의해 잘못 사용되는 것도 막고 (2) 서로 다른 low-level 하드웨어 디바이스를 조작하기 위해 간단하고 통일된 메커니즘을 애플리케이션에 제공한다.

운영체제의 abstraction은 process, virtual memory, files로 이루어져 있다. 파일은 I/O 디바이스의 abstraction 이며, 가상 메모리는 메인 메모리와 I/O 디바이스의 abstraction, 프로세스는 프로세서와 메인 메모리, I/O 디바이스의 abstraction 이다.
Process
프로세스는 프로그램이 메인 메모리로 올라와 실행이 되고 있는 상태를 말한다. 보통 동영상을 보면서 채팅을 하는 등의 여러 프로그램을 동시에 요청하는 경우가 잦다. 이렇게 여러한 프로세스를 한꺼번에 처리하는 방법에는 "병행처리"와 "병렬처리" 두 가지 방법이 있다.
- 병렬 처리: 멀티 코어 프로세서는 여러 프로그램을 동시에 실행할 수 있다. 코어 개수 대로 프로그램을 동시에 수행할 수 있는 것을 "병렬처리" 라고 한다. 2개 이상의 코어가 각기 다른 프로세스의 명령을 실행해서 각 프로세스가 같은 순간에 실행되도록 하는 것이다. 이렇게 여러 코어가 프로세스를 n 개씩 ‘병렬’로 분담해서 하는 것을 multi processing 이라고한다.
- 병행 처리: 하나의 코어가 여러 프로세스를 돌아가면서 조금씩 처리하는 것 이다. 동시에 하는 것은 아니지만 프로세스를 이동하면서 조금씩 처리를 해나가는 것이다. 이를 context swtiching 이라고 하며 매우 빠르게 수행되어 동시에 실행되는 것처럼 보인다
프로그램이 효율적으로 설계되었다면, 코어가 프로세스를 "병렬"처리하고 각 프로세스를 "병행" 처리한다.

두 개의 동시 실행 프로세스가 있다. - 쉘 프로세스와 프로그램 프로세스
(1) 처음에 쉘 프로세스는 혼자 돌고 있으며, 쉘 커맨드 라인에 입력을 기다린다. (2) 프로그램 실행을 요청하면, 쉘은 우리의 요청을 실행하기 위해 운영 체제로 컨트롤(control)를 전달하는 시스템 호출(system call)이라는 특수한 함수를 호출한다. (3)운영체제는 쉘의 context를 저장하고, (4)새 프로그램 프로세스를 생성한다. 그리고 나서 (5)새 프로세스로 컨트롤을 전달한다.(6) 프로그램이 종료된 후 운영체제는 쉘 프로세스를 복원하고 컨트롤을 가져온다. 이후 다시 커맨드 라인 인풋을 기다린다.
한 프로세스에서 다른 프로세스로의 전환은 운영체제 커널(kernel) 에 의해 관리된다. 즉, 운영체제 시스템 자원 관리를 하는 역할이다. 커널은 운영체제 코드중 일부이며 항상 메모리에 상주한다. 애플리케이션 프로그램이 읽기와 쓰기와 같은 운영체제에 의한 어떠한 액션을 요구할때, 이는 system call 을 호출하고 커널에게 컨트롤을 넘긴다. 커널은 요청된 작업을 수행하고 다시 프로그램으로 돌아온다. 커널은 별도의 프로세스가 아니고, 시스템이 사용하는 모든 프로세스를 관리하기 위한 코드와 데이터 구조다.
Threads
한 프로세스 안에 하나 이상 진행될 수 있는 일의 단위를 스레드(Threads)라고 한다. 현대 시스템에서 프로세스는 여러 실행의 단위 스레드로 구성된다. 각각은 프로세스 컨텍스트를 실행하고 같은 코드와 전역 데이터를 공유한다.
Process VS Threads
프로세스는메모리를 차지하며, 때문에 멀티프로세싱에서는 프로세스 수만큼 메인 메모리를 필요로 한다.
스레드의 경우 프로세스의 하위 작업으로, 메모리를 메모리를 차지하지 않고 한 프로세스에 할당된 메모리 공간을 공유한다. 메모리 공간을 공유하는 만큼 프로세스 설계시 주의깊게 진행하여아한다.
Virtual Memory

운영체제에서는 프로세스 생성 시 마다 메모리를 할당해준다. 이러한 프로세스 생성에는 커널 코드, 프로그램 등 다수의 작업을 포함한다. 그러나 메모리 공간은 제한되어 있는 만큼, 프로세스 생성에 제한이 생긴다. 때문에 메인 메모리를 하드디스크 까지 확장해서 공간을 넓혀 사용하는 것을 가상 메모리(virtual memory)라고 한다.
프로세서(CPU)는 가상 메모리 만큼 있다고 치고 프로세스를 운영한다. 실제 물리적인 메모리크기는 더 작기 때문에 하드 디스크에 필요한 데이터들을 저장해 두고 필요할때마다 메모리에 올려 쓴다. 즉, 메모리를 디스크의 캐시로써 사용한다. 여기서 하드 디스크에 올려쓰는 파일을 스왑파일(Swap file)이라고 한다. 가상 메모리 확장을 위해 필요한 파일이다. . 새로운 프로세스 할당이 요구되면, 덜 사용되거나 사용한지 오래된 것들은 메모리에서 내리고, 하드디스크에 올린다.
각 프로세스는 가상 메모리 공간(virtual address space) 이라는 통일된 구조를 사용한다. 리눅스에서 주소 공간의 가장 위쪽은 모든 프로세스에 공통적으로 적용되는 운영체제 시스템 코드와 데이터가 들어간다. 아래 쪽에는 유저 정의의 데이터와 코드가 들어간다.
- Program code and data: 코드는 모든 프로세스가 같은 고정된 주소에서 시작한다. 코드와 데이터 영역은 실행가능한 오브젝트 파일 내용으로부터 직접적으로 초기화 된다.
- Heap: 코드와 데이터 영역 다음에는 실행 시간 동안 동적으로 할당되는 힙(heap) 영역이 바로 이어진다. 프로그램이 실행될때 고정된 크기인 코드와 데이터 영역과는 다르게 힙은 동적으로 확장되거나 줄어들 수 있다.
- Stack: 유저의 가상 주소 공간의 가장 위쪽은 컴파일러가 함수 호출 수행을 위해 사용하는 유저 스택(user stack) 이다. 힙과 같이 유저 스택은 프로그램 실행 중 동적으로 확장하거나 줄어들 수 있다. (호출 시에는 스택은 늘어나고 함수가 리턴되면 줄어든다)
- kernal virtual memory: 가상 주소 공간의 위쪽은 커널을 위한 공간이 에약되어 있다. 애플리케이션 프로그램은 해당 공간의 내용에 쓰거나 읽을 수 없고 직접적으로 커널 코드에 정의된 함수를 호출할 수 없다. 이러한 작업들은 커널을 통해 호출해야한다.
File
파일은 일련의 바이트이며, 그이상 그이하도아니다. 키보드, 디스플레이, 네트워크를 포함한 모든 입출력 디바이스는 파일로 설계된다. 시스템 내에서 모든 인 풋과 아웃 풋은 Unix I/O라고 알려진 시스템 콜을 사용하여 파일 읽기와 쓰기로 수행된다.
참고 문헌
- Computer Systems: A Programmer's Perspective
- 한빛 미디어